Today at work a colleague raised the issue of which browsers we were planning to support. Naturally, supporting a browser also means testing on a specific version of a specific browsers, which, quite simply put, means more test effort, probably more coding effort, and therefore more time spent.
After a discussion with our product owner they settled on the latest stable version of four browsers. The product we were working on before supported two browsers, Internet Explorer and Firefox, with Internet Explorer being the one to optimize for, especially since one of the third party products only supported IE. Now we added Chrome and Safari to the list.
The same colleague also complained that he currently uses three browsers, sometimes simultaneously. I realized, I do too.
On Vista I use Chrome for most things. Now I know that it lacks the tons of add-ons that Firefox offers, but I just love it. I love that the design is very simple and focuses on the actual web pages rather than menu and status bars. Mostly I love typing in anything into the address field. I’ve gotten so used to it that I forget that other browsers use extra fields for Google searches and just typing my search words into IE’s or Firefox’s address bar. If there’s one thing I need other browsers to copy from Chrome, it’s this.
However, I understand that people still prefer Firefox. The fact is that I have never actually been an avid user of add-ons. I’ve had my favorite Firefox add-ons, mostly webdesign stuff like the color picker or the ruler and these were awfully helpful and cool. FireBug as well is an awesome tool for web developers. But I’ve never heavily relied on any add-ons which might have been the reason why switching to Chrome went so smoothly for me.
I still use Firefox occasionally, though, mostly when I need one of the add-ons I have installed or whenever a page doesn’t look quite so right in Chrome (still happens).
I use IE mostly for anything that relies on using IE, which sadly happens often enough. Now, I’m not even sure whether there’s still reason to hate IE (given that we’re two versions away from IE 6 it seems like the grunting phase should be over), I just still prefer Firefox and probably wouldn’t use IE if it wouldn’t rock the whole Outlook webmailing thing and wasn’t necessary to run some of Microsoft’s web applications (yes, MS Project, I’m looking at you). Plus, of course, given that IE is still widely used, it’s the browser I most often use when developing.
What I’m trying to say is that it’s gotten hard to settle for one browser, for three reason. First, sometimes you just can’t. Some pages or web applications just run or look better on a specific browser (and some will only run on a specific browser). Second, browsers seem to have their own personalities. Chrome is awesome for the whole browsing, social, fun, interactive stuff and in my opinion just generally awesome. Firefox is great because of its vast library of add-ons and because it’s really really good. IE still beats other browsers for some of the more conservative sites, probably because a lot of sites are still optimized for IE.
Last of all, the feeling I have is that all major browsers are actually getting pretty good, so there’s not a clear winner anymore. For most people that just means that they can just pick what they like best. For a geek girl like me it means that I can’t even settle on one for good.
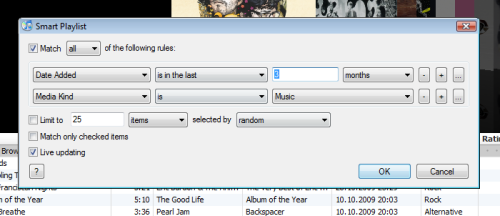
In other news I fixed a small thing that was bugging me on iTunes. I like listening to my recently added items, but since I use my iPod for audiobooks and movies as well, these files were always mixed in between, which is especially annoying when you’re on your kickboard on the way to the train and don’t have the time to fiddle with your iPod just to skip that audiobook chapter or that episode of House.
Now, I could have realized that sooner, but of course, „Recently Added“ is just another Smart Playlist and perfectly editable. The only change I had to make was filtering it down to media kind and everything was as I wanted.